
We were reviewing a Kubernetes manifest for a 3rd party integration. It was a service from a well-known vendor and included read-only access to /var/. Read-only typically means exactly what it says on the tin: no writing, no deleting, no mutable actions allowed. It feels like that should apply to everything in the mount. And on first pass, most of the reviewers were in the “sounds good to me” camp for exactly that reason. Once it made the rounds and raised concerns, the vendor themselves defended the mount with “well it’s read-only”.
If you know where this is going (that read-only permissions don’t apply to sockets and there’s some serious goodies in /var/) then there’s nothing too surprising coming up. If not, buckle up because we’re going to use a seemingly innocent manifest to escape from a Kubernetes container and write some files on the host! ![]()
And obligatory but important: Use information here only for systems you have permission to operate on.
The Breakout
What Are We Actually Lookin’ At
Take this example manifest:
apiVersion: v1
kind: Pod
metadata:
name: hello-world-service
spec:
containers:
- name: hello-world
image: hello-world:latest
imagePullPolicy: Always
command: ["sleep", "infinity"]
securityContext:
capabilities:
drop:
- ALL
volumeMounts:
- name: var
mountPath: /var
readOnly: true
volumes:
- name: var
hostPath:
path: /var
type: Directory
Having a host mount at all should raise eyebrows, but assuming there’s some justification for it I’d dare say that manifest passes the sniff test. The container drops all Linux capabilities, /var/ is Linux’s store for variable data, logs, and temporary file kind of stuff, and we’re clearly only granting read access to it. So sure, maybe we have some kind of SIEM service that’s aggregating logs, this looks like a very fair config.
How Juicy Is /var Really, though?
Here’s the jam. /var/run/ includes the runtime socket for containerd (and docker and probably others, but here we’re using containerd). That’s the socket that start, stops, kills containers, and pulls images. It’s the socket that offers the container runtime API to the Kubernetes controller. It’s everything. And the only authorization here is provided by Linux’s file permissions, the API itself has none. And, for reasons I’ll get into a little more later, the readOnly: true config means nothing for a socket. So the seemingly innocent manifest above actually grants carte blanche access to the container runtime, which itself usually runs with significant permission, and we’re going to leverage that to increase our own privilege.
Taking Advantage of This
I’m not for a moment implying a trusted vendor would do anything like this to escalate permissions, that’s bananas. I am implying that supply chain compromise is a real, regular reality, and any exploit in a 3rd party can immediately become your own. So imagine we’re a 4th party attacker who’s silently compromised a trusted 3rd party. We’re running code in a Kuberenetes pod like above, including read access to all of host /var/. How do we exploit the situation to escalate privilege and take full control of the host?
We’re going to abuse our powers and launch a more privileged image and pivot from there. To recap, here’s our situation:
- We (the 4th party attacker) have the ability to run untrusted code in a trusted pod
- The trusted pod is running with the above k8s manifest

- The goal is to escape the container and get access to the node
Step 1. What’s Easy: Killing Processes
Enter tools like ctr and crictl. They’re CLIs that you can point to that /var/run/containerd.sock and interact directly with containerd API. And if you run those in the compromised container, you’ll quickly discover that you can do something like this:
$ ctr --address /var/run/containerd/containerd.sock containers list
$ ctr --address /var/run/containerd/containerd.sock containers delete <choose a container id>
and delete one of the other containers running in the cluster, no questions asked. Solid start, but we’re looking to get to the host here, not just wreck havoc.
Step 2. What Isn’t Easy: Launching an Arbitrary Image
What we’d really love to do is run our own image, from our own registry. When you do the above, especially paired with the ctr man page for container create, you’d think running any abitrary image is one short step away. But no, it’s actually a major hurdle. Remember a container image is basically a filesystem that contains what an application needs to run. When launching a new image a few key things happen:
- The runtime pulls the image
- The runtime prepares the filesystem, defining the container
- The runtime starts a task in that container
WTF is a Snapshotter and Why’s it In Our Way
Step 2 is actually quite hard. Remember we’re giving instructions to the containerd runtime, but that runtime itself is a process on the host. So when it gets to referencing a prepared filesystem for the container, if it’s told the filesystem is prepared at /tmp/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/<snapshot-id>/fs, it’s going to look in the host’s /tmp/, not the current container’s. And we don’t have permission to add or modify mounts.
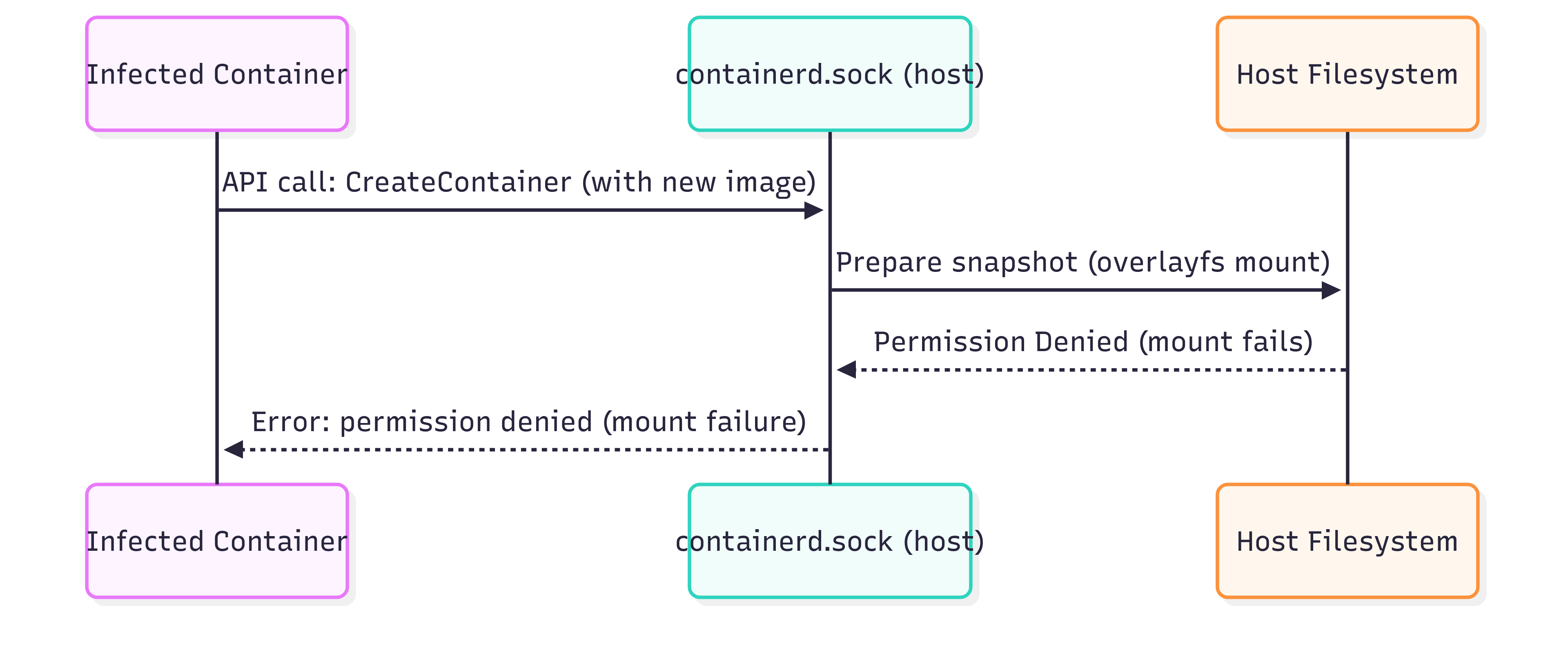
Even though we can talk to containerd, when we ask it to create a new container, it tries to prepare a new overlayfs snapshot on the host. Since the host filesystem is read-only, this step fails with a “permission denied” error. That’s why simply requesting containerd to launch a new image from inside a container doesn’t work as easily as it seems like it might.
Solution: Reuse Prepared Snapshots
What do we really want though? The goal isn’t really to run our own image, it’s to run our own code (to then wiggle out to the host). So… let’s just aim for a shell. Well lucky us, we’re already running in a k8s context that’s launched oodles of images, and they’ve been prepared in the host directory we have read access to. So let’s simply look through the already prepared filesystems for a shell.
snapshotsDir := "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots"
entries, err := ioutil.ReadDir(snapshotsDir)
if err != nil {
log.Fatalf("Failed to read snapshots directory: %v", err)
}
var rootfsPath string
for _, entry := range entries {
if entry.IsDir() {
fsPath := filepath.Join(snapshotsDir, entry.Name(), "fs")
if _, err := os.Stat(fsPath); err == nil {
shPath := filepath.Join(fsPath, "bin", "sh")
if _, err := os.Stat(shPath); err == nil {
rootfsPath = fsPath
break
}
}
}
}
Seems silly, but baby is that effective. If there’s any shell in any image already present, it’ll just identify which one. Then there’s an image we know can be reused to run arbitrary shell code.
Step 3. Escalate Privilege and chroot
I’m purposelly skipping some interesting steps here, because this blog is a word of caution, not an exploit manual. But the steps from here are honestly not any more than mildly interesting, you should assume any attacker who can read API docs has a fresh container running at this point, and it has the host / mounted and cat /proc/$$/status | grep Cap shows it’s granted the default capabilities (including those that were explicitly dropped in the original container!)
From this new container, it’s a short:
chroot /host /bin/sh
useradd steve
echo "steve:p@ss" | chpasswd
to establish a persistent user on the node. Note that, originally, not only did we not have a full host / mount, we didn’t have the Linux capability that’d allow calling chroot, either.
We’ve escalated, escaped, and now have a user we can use on the host. If you’re more a visual ![]() person, then
person, then touch /tmp/hi_i_was_here is also stellar proof.
So mission accomplished, we escaped and are tromping around the node.
Should This Be Obvious?
I want to spend another minute on why it’s reasonable that this would be an accepted config to start with. If you don’t buy into the idea that this is not common knowledge in the security community, note that sources on the internet are all over the place. Some recognize the risk, others don’t and imply read-only is safe.
From Bottlerocket’s security guidance:
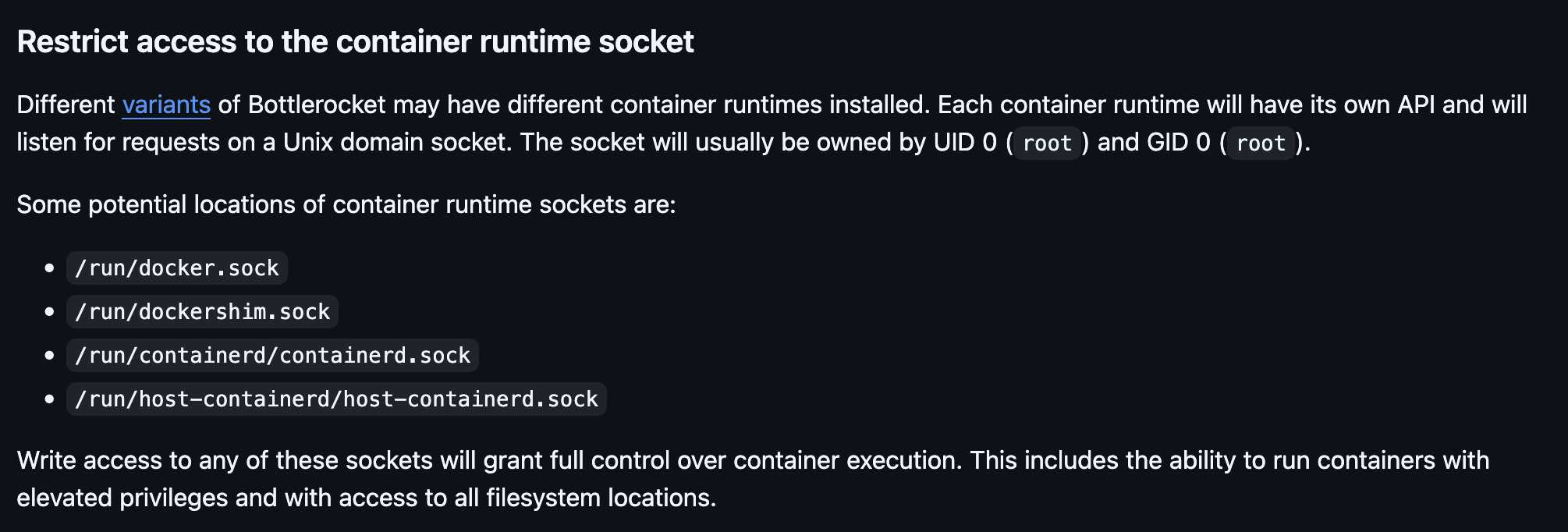
This is just one of the most reputable examples I know of, there’s many more in random blogs and StackOverflow answers. In fact there’s enough verbiage online implying that readOnly: true makes for a safe configuration that Google’s Gemini has learned to confidently asset that’s the case.
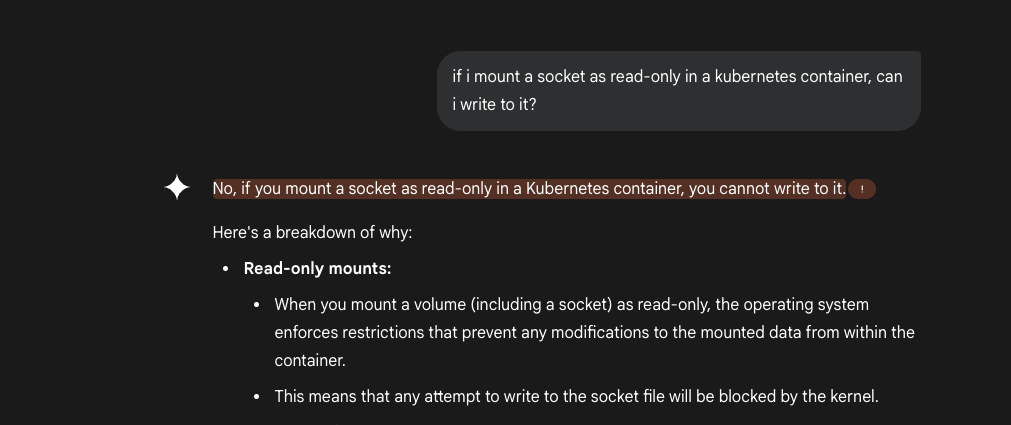
And even as I’m writing this post, using VS Code with Copilot enabled, I asked Copilot to read what I’ve written and suggest remediations I’ve not already mentioned. Despite an entire blog of context focused precisely on read-only mounts not being a protection for sockets, it still suggested “make it read-only and drop caps”. ![]()
Why Is It Like This?
Why’s it like this, anyway? It’s because sockets are interprocess communication (IPC), files are part of the filesystem, and in Linux these are totally separate things. The Kubernetes read-only config employs the virtual filesystem in Linux to make sure there are no modifications made to any filesystem resources. That enforcement includes POSIX calls like open. Connecting to a socket is just not part of that stack, the POSIX call is connect, and it’s entirely outside of the filesystem’s purview. Unless you’ve been here and are already familiar for one reason or another, I don’t think the distinction is really at all obvious.
What you get with a read-only /var/ mount is no ability to change the name of the socket file, or delete it, or create a new one. But nothing at all preventing you from connecting to what exists and sending/receiving traffic over that connection.
How to Guard Against This
Don’t Mount Sockets At All
This one is obvious I guess. Don’t mount a socket to start with.
Don’t Have Any Shells, Anywhere
Is “no shells anywhere in the cluster” really plausible? Maybe. I dunno. If you try hard enough, probably. Note any interpreter (python, node) would still have allowed arbitrary code execution in a escalated container. It might have stopped the chroot total takeover, but there’s better hackers than me out there, so while it’s for sure a helpful mitigation, I wouldn’t count on it to stop an advanced threat.
Go Harder on Least Privilege
“Least privilege” doesn’t mean just not granting the host mount, it could have also been restrictions with tools like SELinux. Those extra security guards could have prevented the socket connection, or the filesystem preparation, or chroot to the host and the mutable actions we took in the last mile.
Or, if it is a SIEM tool, maybe it could have simply specified /var/log and not just /var. In this case that would have made all the difference.
It could have also been prevented by using non-root users in the original container, since those are the permissions enforced by Linux when evaluating connect to the runtime socket. Or using user namespacing, so the UID 0 in the container wasn’t allowed to actually connect to the socket owned by UID 0 on the host.
Basically, as least privilege goes, even simple restrictions could have made this much harder.
Conclusion
I think the point is some non-obvious things have major impacts, and this is one of them. Or maybe it’s to be careful how much you trust 3rd parties (and AI). Or it’s just clarifying and adding detail to an issue that I found confusingly hard to find clarity or get detail on. I suppose it’s all the above.


Leave a Comment