
I wrote a neural network and was glad to see it perform well learning XOR and other basic functions, but scaling it to recognize handwritten characters introduced more unpredictable performance. It demonstrated some successes polluted with frequent rounds of complete nonsense; series where the success rate was worse than even a random guess.
To try to get a better grasp of exactly what was happening, I wrote a test to graph performance as the network scaled from 10 – 200 neurons per input and hidden layer. The function being taught was constant and always with 5,000 training iterations. The graph generated gave me no answers, just more confusion! There seemed to be about a 50/50 chance of relative success or complete failure, nothing in between. Also, subsequent runs saw different results at each size.
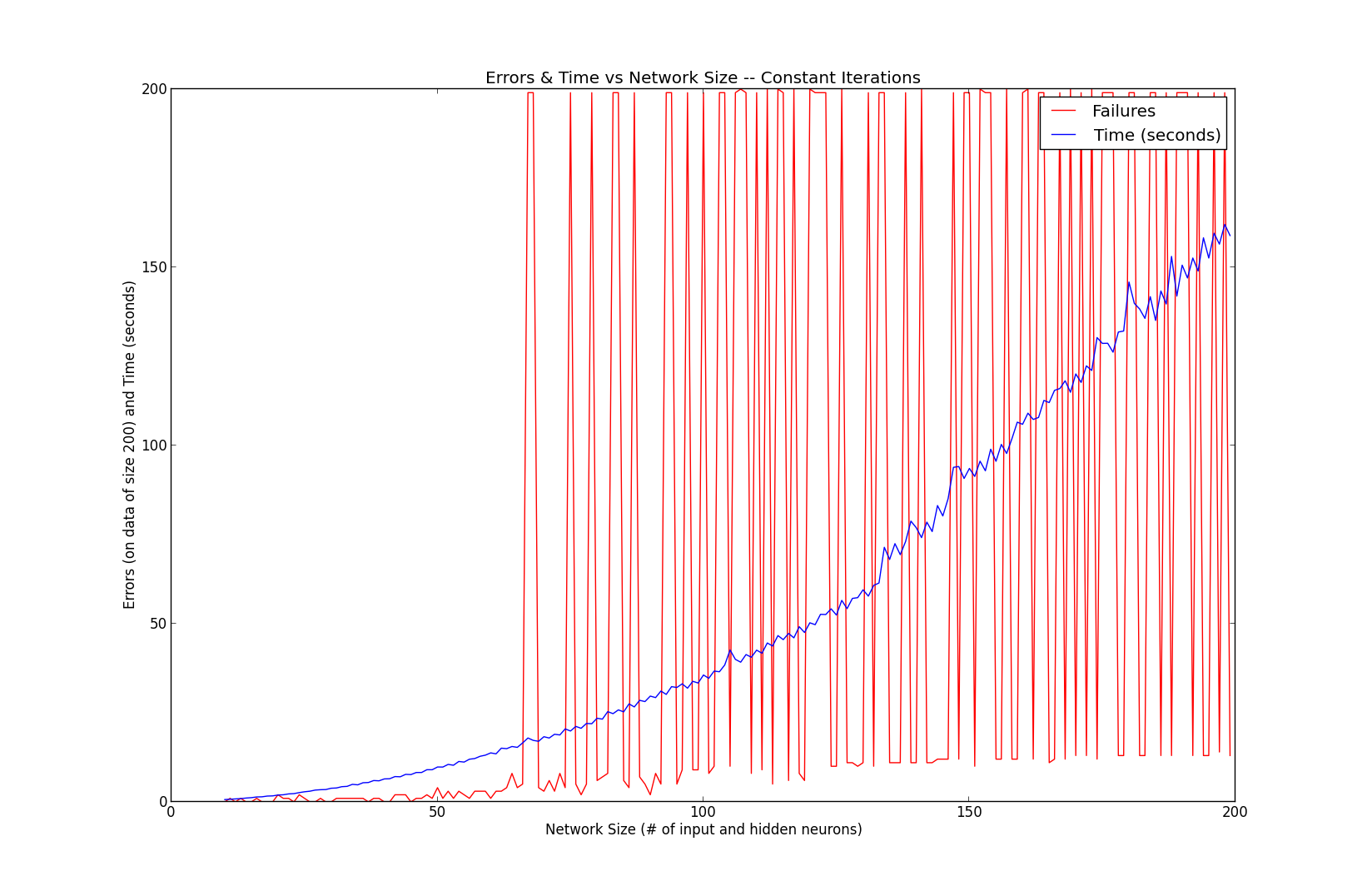
After some research I became suspicious of local minima. The larger and more complex a network and data set become, the greater chance of getting stuck in a local minimum of the function. After some trial and error and about a dozen hours of testing (one complete run through this test takes ~3 hours) a hint on Stackoverflow encouraged me to decrease the learning rate. Ultimately, that was the winning tip. The graph above was generated with a learning rate of 0.5 and momentum coefficient of 0.3. Decreasing those to 0.2 and 0.1, respectively, yielded much better results; nearly perfect scores.
“Check out” the whole project on Github. The test that generates these graphs can be seen in test.py, method testLargerNetworks().

Leave a Comment